Bitquery Kafka Streams - Understanding Concepts
Bitquery provides realtime data via Kafka as well in addition to GraphQL subscriptions. In this section, we'll see how Kafka-based streaming works and how to integrate it into your application using practical code examples. For price data streams, check out our Crypto Price API Kafka topic.
How to Get Access to these Streams?
IDE credentials will not work with our Kafka Streams. You need a separate username and password. Please contact sales on our official telegram channel or fill out the form on our website.
Pro and Cons
Kafka provides faster and more reliable streams comparing to GraphQL subscriptions due to the following advantages:
- It has lower lattency due to the shorter data pipeline, as GraphQL subscriptions involve custom databases and additional logic to process, filter and format the data
- Better reliabilty of the connection protocol compared to WebSocket interface, better optimised for persistent connections
- Messages from Kafka topic can be read from the latest offset, it is possible to create consumers that have all messages without gaps and interruption.
- Scalability is better as multiple consumers may split the load to consume one topic, automaticlly redistributing load on them
There are some disadvantages however compared to GraphQL subscriptions:
- There is no way to consume Kafka streams in browser. You can only use it only on server side.
- It is not possible to pre-filter or re-format messages on Kafka streams, as schema is pre-defined, and you need to make all post-processing in your code. Some calculations, as usd value of trade have to be executed on client side as well
- IDE does not support Kafka streams yet, debugging the code have to be done on consumer side
Kafka streams contains same set of data as GraphQL subscriptions, and the decision which one to use dependent more on your application type. Consider the following factors when selecting which technology to use.
Consider using GraphQL if:
- You are building a prototype and the speed of development is a primary factor for you. Integrating GraphQL is easier, IDE helps to de-bug queries and see the data you receive in application;
- Your application uses archive and real-time data altogether. GraphQL has a unified interface to query and subscribe the data streams, that makes such application easier to build and maintain;
- Your application provides different data on web pages, for example show price diagrams for trading. Then GraphQL makes simpler to filter the data and make queries based on page content;
- There is no server side for your application, or it is minimal. Then GraphQL can be integrated directlty to JS client code;
Consider using Kafka if:
- Latency is the most important factor and you building fast scalable application in cloud or on dedicated servers;
- It is not acceptable to lose any single message from the stream, you need persistent reliability;
- You have a complex calculations, filtering or formatting of the data that GraphQL does not deliver. Then instead of consuming unfiltered stream from GraphQL consider switch to Kafka.
This decision sometimes not straightforward, consult our sales and support team, we will help you find optimal solution.
Important Notes about Kafka Streams
- Stream is not filtered, it contains all the messages with a complete data for every topic. It means you need to have a good throughput network, fast server and code to efficently consume and parse it;
- Granularity of data message is different in topics, depending on the nature of the data.
- It is not guaranteed that the message will come in sequence of the block number, time or any other attribute.
- Messages in topic may have duplicates. If this is a problem, your code must have a storage or the cache to remember which messages are already processed to avoid double processing.
- Large messages can be separated on smaller ones, as Kafka does not allow pass more than 1 Mbyte in one message. For example, first 1200 transaction may come in one message, and the remaining 1000 will follow in another.
- Transactions themselves will never be split: each transaction record is always delivered in full. If a single transaction payload exceeds Kafka’s maximum message size, the producer will receive an error—Kafka will not peek inside the payload to automatically fragment it into multiple messages.
Kafka Streams Lattency
Topics for the same blockchain are not equal by lattency. If you have requirements on lattency, consider to select the proper stream for your application:
- Broadcasted topics are available for most blockchains. They can be faster, as the transactions are not waiting till include and commit the block in the chain
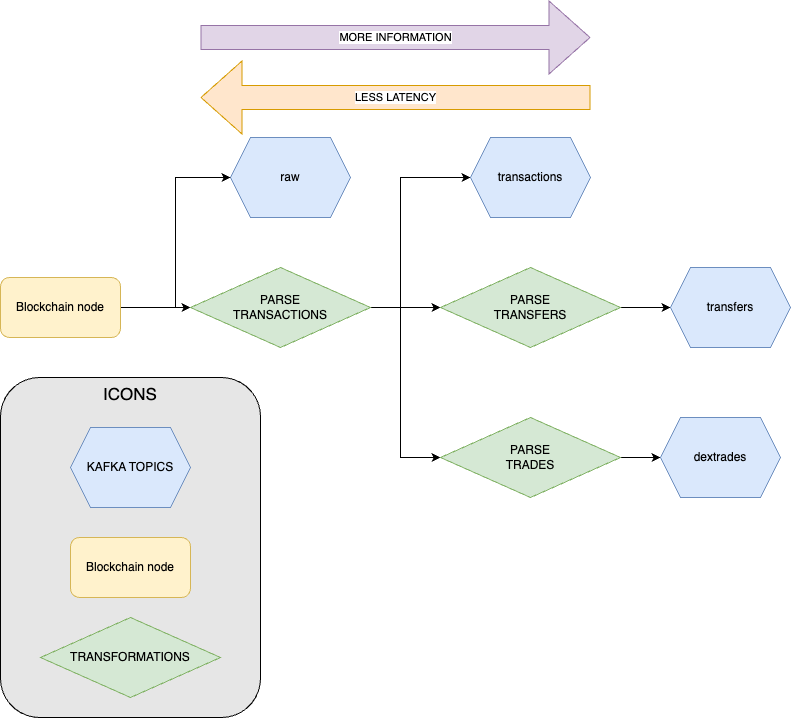
- Streams are chained while they are parsing, the closer the topic to the original blockchain node, the less is the lattency. Consider selecting the closest topic that you can effectively parse. Every transformation introduces 100-1000 msec latency in the overall topic delay.
The diagram shows the data pipeline of the streams on the way to KAFKA topics. Broadcasted and committed transaction datapipelines are identical:
Consuming Messages
Your application must implement the code:
- Connect to Kafka server;
- Subscribe to particular topic(s);
- Read and parse messages;
Retention Period of Messages
Proto Streams: Messages are retained for 4 hours.
Connect to Kafka Server
To connect to Bitquery’s Kafka streaming service, you’ll need the following:
- Kafka Broker Addresses
Use the following server list:
rpk0.bitquery.io:9092,rpk1.bitquery.io:9092,rpk2.bitquery.io:9092 - Authentication Credentials
A username and password for SASL over PLAINTEXT authentication – provided by the Bitquery support team.
Non-SSL Connection (SASL_PLAINTEXT )
If you prefer to connect without SSL, you can use SASL_PLAINTEXT on port 9092. This does not require certificates:
sasl_conf = {
'bootstrap.servers': 'rpk0.bitquery.io:9092,rpk1.bitquery.io:9092,rpk2.bitquery.io:9092',
'security.protocol': 'SASL_PLAINTEXT',
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': '<YOUR USERNAME HERE>',
'sasl.password': '<YOUR PASSWORD HERE>',
}
Use plaintext only in trusted or local environments, as the connection is not encrypted.
SSL Connection (SASL_SSL )
If you prefer to connect with SSL, you can use SASL_SSL on port 9093. This requires certificates which can be accessed here
sasl_conf = {
'bootstrap.servers': 'rpk0.bitquery.io:9093,rpk1.bitquery.io:9093,rpk2.bitquery.io:9093',
'security.protocol': 'SASL_SSL',
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': '<YOUR USERNAME HERE>',
'sasl.password': '<YOUR PASSWORD HERE>',
'ssl.key.location': 'client.key.pem',
'ssl.ca.location': 'server.cer.pem',
'ssl.certificate.location': 'client.cer.pem',
'ssl.endpoint.identification.algorithm': 'none'
}
Subscribe to particular topic(s)
To receive messages you first create consumer and subscribe it to a topic or list of topics.
General pattern of the topic name is:
<BLOCKCHAIN_NAME>.<MESSAGE_TYPE>
<BLOCKCHAIN_NAME>.broadcasted.<MESSAGE_TYPE>
General Message Types
MESSAGE_TYPE is specific on blockchain, most blockchain has topics for:
- dextrades - events from DEX trading
- transactions - events, calls, transactions
- tokens - token and coin transfers events
- raw - blocks or transactions directly from node
Refer to Bitquery Streaming Protobuf schemas for structure.
EVM Chains
Broadcasted (Mempool-level):
*.broadcasted.transactions.proto→ParsedAbiBlockMessage*.broadcasted.tokens.proto→TokenBlockMessage*.broadcasted.dextrades.proto→DexBlockMessage*.broadcasted.raw.proto→BlockMessage
Committed Blocks:
*.transactions.proto*.tokens.proto*.dextrades.proto*.raw.proto
Complete List of Topics
All topics deliver data in protobuf format. JSON samples for inspection: kafka-data-sample.
Multi-chain trading topics
The trading namespace defines two Kafka topics. Both use the same credentials as your subscription:
trading.prices— Multi-chain Price Index Streams. See the Crypto Price API for usage.trading.trades— Real-time DEX trades aligned with the Crypto Trades API. Message structure is defined inmarket/trades.protoin Bitquery Streaming Protobuf.
EVM chains
Committed topics use:
*.transactions.proto→ParsedAbiBlockMessage*.tokens.proto→TokenBlockMessage*.dextrades.proto→DexBlockMessage*.raw.proto→BlockMessage
Mempool / broadcasted topics insert broadcasted immediately after the chain prefix (example: eth.broadcasted.transactions.proto). They use:
*.broadcasted.transactions.proto→ParsedAbiBlockMessage*.broadcasted.tokens.proto→TokenBlockMessage*.broadcasted.dextrades.proto→DexBlockMessage*.broadcasted.raw.proto→BlockMessage
*.dexpools.proto streams are described under the DEXPools Cube documentation.
Ethereum (eth)
eth.transactions.proto→ParsedAbiBlockMessageeth.tokens.proto→TokenBlockMessageeth.dextrades.proto→DexBlockMessageeth.dexpools.proto— see DEXPools Cube documentationeth.raw.proto→BlockMessageeth.broadcasted.transactions.proto→ParsedAbiBlockMessageeth.broadcasted.tokens.proto→TokenBlockMessageeth.broadcasted.dextrades.proto→DexBlockMessageeth.broadcasted.raw.proto→BlockMessage
BNB Chain (bsc)
bsc.transactions.proto→ParsedAbiBlockMessagebsc.tokens.proto→TokenBlockMessagebsc.dextrades.proto→DexBlockMessagebsc.dexpools.proto— see DEXPools Cube documentation
Where enabled, bsc.broadcasted.* topics follow the same mapping as eth.broadcasted.*.
Base (base)
base.transactions.proto→ParsedAbiBlockMessagebase.tokens.proto→TokenBlockMessagebase.dextrades.proto→DexBlockMessagebase.dexpools.proto— see DEXPools Cube documentation
Where enabled, base.broadcasted.* topics follow the same mapping as eth.broadcasted.*.
Polygon (matic)
matic.transactions.proto→ParsedAbiBlockMessagematic.tokens.proto→TokenBlockMessagematic.dextrades.proto→DexBlockMessagematic.dexpools.proto— see DEXPools Cube documentationmatic.predictions.proto— prediction markets; decode using Bitquery Streaming Protobufmatic.broadcasted.predictions.proto— prediction markets (broadcasted)
Where enabled, matic.broadcasted.* topics for standard EVM transactions, tokens, dextrades, and raw streams follow the broadcasted mapping above.
Optimism (optimism)
optimism.transactions.proto→ParsedAbiBlockMessageoptimism.tokens.proto→TokenBlockMessageoptimism.dextrades.proto→DexBlockMessage
Where enabled, optimism.broadcasted.* topics follow the same mapping as eth.broadcasted.*.
Robinhood (robinhood)
robinhood.transactions.proto→ParsedAbiBlockMessagerobinhood.tokens.proto→TokenBlockMessagerobinhood.dextrades.proto→DexBlockMessagerobinhood.raw.proto→BlockMessage
Bitcoin
btc.transactions.proto— decode using Bitquery Bitcoin protobuf definitions in Bitquery Streaming Protobuf.
Solana (solana)
solana.transactions.proto→ParsedIdlBlockMessagesolana.tokens.proto→TokenBlockMessagesolana.dextrades.proto→DexParsedBlockMessage
Tron (tron)
Message types per topic are defined in Bitquery Streaming Protobuf for Tron.
tron.raw.prototron.transactions.prototron.tokens.prototron.dextrades.prototron.broadcasted.raw.prototron.broadcasted.transactions.prototron.broadcasted.tokens.prototron.broadcasted.dextrades.proto
Contact our support team for the topics that you can connect to for your specific needs.
When subscribing, you also specify some important properties:
-
Configuration for offset management. It is done a bit differently in Kafka libraries, but the idea is that you have a choice of:
- receiving only latest messages, the next time you re-connect it will re-wing to the last one. It is controlled by config:
autoCommit: false, fromBeginning: false, auto.offset.reset: latest - or you want to consume all messages and do not lose any. Note that in this case when you re-start your server you will have a gap as it starts reading from the last message you received!
You have to configure it as:
autoCommit: true, fromBeginning: false, auto.offset.reset: latest. Check https://docs.confluent.io/platform/current/clients/consumer.html#offset-management-configuration for more info.
- receiving only latest messages, the next time you re-connect it will re-wing to the last one. It is controlled by config:
-
Group ID. Group ID you have to specify when creating a consumer. It must start with your username. In most cases you need just one group ID that can be set the same as username. You may need several group IDs in an advanced configuration when you using multiple independent applications consuming same stream.
Note that you can deploy many instances of your application with same Group ID for fault tolerance and better performance. Then only one instance will receive the message from the topic, automatically re-distributing the load across your servers.
Typicaly you need setup of one consumer per one topic, as the message parsing for them anyway will need different code.
Note: For Price of a Token in DEXTrades topic, you need to calculate it using the amounts.
Read and parse messages
Your consumer will read messages from the topic, and you will be able to parse them.
- Depending on the setting you used to subscribe to topic, you will read the last message, or some message on the past that is the net message to read.
- If you do not read messages fast enough, the lag will be accumulated, and the latency will grow.
- Message in topic is Protobuf. Parse proto code is specific for programming language that you use, but should be very simple.
- Message contains the list of objects on the top level. Structure of objects corresponds to the topic that you consume. General schema is described in https://github.com/bitquery/streaming_protobuf.
What to Know About Protobuf Streams?
- Lower Latency: These streams are delivered before the block closing message appears on the node, resulting in less lag from the transaction to the stream.
- Block Header Completeness: The block header in messages may not be complete; only the
Slotfield is guaranteed to be correctly set. - Compact Binary Format: The streams use a binary protobuf format, which is more compact than JSON.
- Strict Schema: Messages adhere to a strict schema defined in Bitquery's Streaming Protobuf for Solana.
- Message Packing: Transactions are packed in small chunks, with no more than 250 transactions per message.
- Message Expiration: Topic messages expire after 24 hours in the stream.
Best Practises
When working with Kafka streams, ensuring efficient message consumption and processing is crucial for maintaining low latency and high throughput. Here are the best practices to follow:
1. Parallel Processing of Partitions
Kafka topics are divided into partitions, and each partition must be read in parallel to maximize throughput and minimize latency.
How Partitioning Works:
-
The Kafka producer sets the message key to:
- Block slot (for Solana)
- Block hash (for EVM chains)
-
This ensures that all messages for a single block/slot are routed to the same partition.
-
Always read all partitions in parallel to prevent message lag.
-
Assign one thread per partition to ensure balanced load distribution.
2. Continuous Message Consumption
- Your consumer loop should never stop unless explicitly shutting down.
- If message processing is needed, process messages asynchronously while keeping the reading loop running.
- Avoid blocking the main consumption loop with heavy computations—delegate processing to worker threads.
3. Efficient Message Processing
- Batch processing can help reduce overhead but should be balanced with latency considerations.
- Use channels and worker groups in Golang for concurrent processing.
Documentation References
Kafka has a lot of documentation in public access, generic and programming-language-specific.
Some links that you may find useful are:
- General Intro to Kafka and Concepts
- Javascript Guild Connecting To Kafka using KafkaJS
- Golang Client Library
- Python Client Library
In addition, you may need a reference to Bitquery schema for messages: