Migrating from API v1 to v2
Overview
V2 APIs are designed to provide real-time blockchain data without any delay. It combines both real-time and historical data. You can read more on the differences here Below, you'll find key changes and instructions on how to adapt your existing v1 queries to the v2 format.
Authentication in v1 vs v2
One of the major differences between v1 and v2 is the way API is authenticated. In v1, you use a API-KEY to authenticate your requests to graphql.bitquery.io.
And in v2, you use OAuth token mentioned as Bearer ory_...yourtoken and authenticate your requests to streaming.bitquery.io/graphql. Read more on how to generate token here.
Changes in Network Specification
- v1: Specified using a generic identifier within a function, e.g.,
ethereum(network: ethereum). - v2: Now requires a more specific
networkidentifier and inclusion of adataset. Example:EVM(network: eth, dataset: combined).
Example Conversion:
-
v1 Query:
query MyQuery {
ethereum(network: ethereum) {
blocks {
count
}
}
} -
v2 Query:
query {
EVM(network: eth, dataset: combined) {
Blocks {
count
}
}
}
Schema and Data Access
The v2 API maintains a similar schema structure but integrates new data cubes such as balanceUpdates, tokenHolders, and DexTradeByTokens. The ability to click-select in the schema builder is still available in v2, facilitating easier transition and query building.
If you're new to v2, check more examples on:
TokenHolder APIs balanceUpdates DexTradeByTokens
Smart Contract Interactions
- v1: Data is accessed through
smartContractCallsandsmartContractEvents. - v2: Simplified to
CallsandEvents.
Handling Arguments and Values
One of the major differences in v2 is how arguments and their values are handled and accessed.
-
v1: Arguments and values are accessed using filters based on the argument name.
token0: any(of: argument_value, argument: { is: "token0" }) -
v2: Arguments are explicitly defined by data type, providing more structured access and clearer query definitions.
Arguments {
Name
Value {
... on EVM_ABI_Integer_Value_Arg {
integer
}
... on EVM_ABI_String_Value_Arg {
string
}
... on EVM_ABI_Address_Value_Arg {
address
}
... on EVM_ABI_BigInt_Value_Arg {
bigInteger
}
... on EVM_ABI_Bytes_Value_Arg {
hex
}
... on EVM_ABI_Boolean_Value_Arg {
bool
}
}
}
Aggregation : From v1 to v2
Let's take this query in v1, where we get total number of unique currencies traded on Ethereum on a particular day. The count and sum aggregation is available in both v1 and v2.
query MyQuery {
ethereum(network: ethereum) {
dexTrades(date: {is: "2024-01-01"}) {
Unique_tokens_bought: count(uniq: buy_currency)
Unique_tokens_sold: count(uniq: sell_currency)
}
}
}
- Date Filtering: Instead of a separate
datefield, v2 usesBlock.Datefor date filtering. - Field Mapping: The
buy_currencyandsell_currencyfields in v1 are mapped toTrade_Buy_Currency_SmartContractandTrade_Sell_Currency_SmartContractrespectively in v2.
query MyQuery {
EVM(network: eth, dataset: combined) {
DEXTrades(where: {Block: {Date: {is: "2024-01-01"}}}) {
Unique_tokens_bought:count(distinct: Trade_Buy_Currency_SmartContract)
Unique_tokens_sold:count(distinct:Trade_Sell_Currency_SmartContract)
}
}
}
Decimals & Precision
In API v1, the decimal precision was low at the GraphQL layer. While the data was saved accurately with all decimals, it would lose precision when processed through GraphQL.
To avoid this issue, in API v2, values are now represented as strings, allowing for exact precision up to 18 decimal places without any loss of accuracy.
Migrating Complex Queries from v1 to v2
Let's take the below query which fetches the latest token details including USD values.
{
ethereum(network: ethereum) {
dexTrades(
options: {desc: ["block.height", "tradeIndex"], limit: 1, offset: 0}
buyCurrency: {is: "0xdac17f958d2ee523a2206206994597c13d831ec7"}
) {
block {
timestamp {
time(format: "%Y-%m-%d %H:%M:%S")
}
height
}
tradeIndex
protocol
exchange {
fullName
}
buyAmount
buyCurrency {
symbol
}
buy_amount_usd: buyAmount(in: USD)
sellAmount
sellCurrency {
symbol
}
sell_amount_usd: sellAmount(in: USD)
priceInUSD: expression(get: "buy_amount_usd / buyAmount")
}
}
}
Now to convert this to v2, let's first tackle the filters.
options: {desc: ["block.height", "tradeIndex"], limit: 1, offset: 0}
buyCurrency: {is: "0xdac17f958d2ee523a2206206994597c13d831ec7"}
In v2, the same filters would be:
limit: {count: 1}
orderBy: {descending: Block_Number}
where: {Trade: {Buy: {Currency: {SmartContract: {is: "0xdac17f958d2ee523a2206206994597c13d831ec7"}}}}}
There is no separate filter called options
Notice we use . in v1 to access inner fields while we use _ in v2.
Next, we select the fields in the response
{
Block {
Number
Time
}
Transaction {
From
To
Hash
}
Trade {
Buy {
Amount
AmountInUSD
Buyer
Currency {
Name
Symbol
SmartContract
}
Seller
Price
PriceInUSD
}
Sell {
Amount
AmountInUSD
Buyer
Currency {
Name
SmartContract
Symbol
}
Seller
Price
PriceInUSD
}
}
}
In v1, we had fields labelled as buyCurrency, sellAmount and so on but in v2 we have nested schema, where we choose
Buy{
Currency
{}
}
The nested schema in v2 requires accessing fields through specific paths, e.g., Trade.Buy.Currency.SmartContract.
Where do I find my Bitquery API v1 key?
To find your Bitquery API v1 key, log in to your Bitquery account, navigate to Applications, and create a new application if needed. Then, visit the Access Tokens page to generate a new access token. This token serves as your API key for authentication. When creating a token, be sure to set an appropriate lifespan to avoid unnecessary interruptions or the need for frequent regeneration.
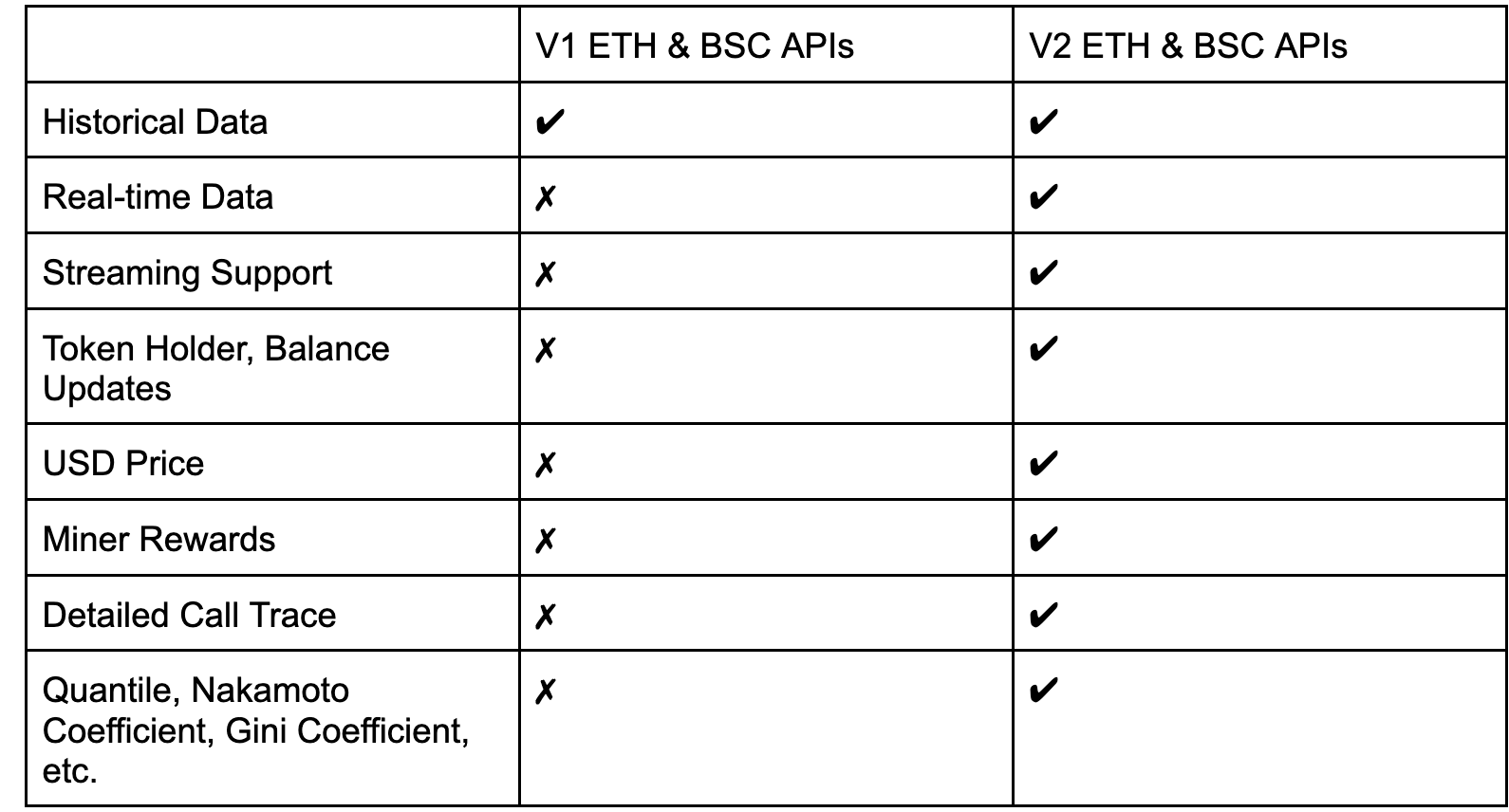
V1 vs V2 : Data Points