Query Principles
You query the data using GraphQL language. Basically it defines simple rules how the schema is defined, and how to query the data using this schema.
Schema
Schema defines what data you can query and which options (arguments) you can apply to the query. Schema allows IDE to create hints to build the query interactively. IDE also shows the schema on query builder and in Document section. Only queries matching schema can be successfully executed.
Schema for blockchain data is pretty complicated, but for your queries you do not need to see it full. You only need a portion of it related to your needs typically.
Query vs Subscription
Query is used to query the data. When you need to get updated results, you must query the endpoint again with the same or another query.
Subscription is used to get data updates. You define a subscription, and after the new data appear, it will be delivered to you without any actions from your side.
This defines the cases, when to use one or another:
- use queries when you need data once, or the data not likely changed during its usage period
- use subscriptions for the "live" data, or when data may be changed while using it
Good news, that queries and subscriptions use identical schemas, except some attributes of the top element, to define the dataset usage. It allows your applications to switch between pull and push modes of operation with a minimal changes of the code and queries.
Compare the code in the first query and the first subscription to see the difference.
This section describes principles that applies to subscriptions as well as to queries. We will show examples for queries, but remember that they applied to subscriptions as well.
Default filters (GraphQL v2)
By default, only successful data is included in results. GraphQL v2 applies the following default filters to both queries and subscriptions. You can override any of them by specifying different values explicitly in your GraphQL filters.
| Data type | Default filter(s) |
|---|---|
| Transactions | success = true |
| Calls, Events, Transfers, Prediction market events, DEX pool events | Call/event success and transaction success = true |
| DEX trades | Trade success = true |
| Trade API market prices | Price_IsQuotedInUsd = true, Interval_VolumeBased = false |
To get failed or non-default data, add an explicit filter. For example, to query failed DEX trades, you must explicitly filter for them (e.g. Failed trades example).
For default limits (query and subscription), see Limits and Subscription default parameters.
Query Elements
Consider the query:
query {
EVM(dataset: archive network: bsc) {
Blocks(limit: {count: 10}) {
Block {
Date
}
count
}
}
}
Dataset Element
Top element of the query is
EVM(dataset: archive network: bsc) {
which defines the type of schema used (EVM, Ethereum Virtual Machine). For different types of blockchains
we use different schema.
dataset: archive network: bsc is an attribute, defining how we query the dataset.
In this case, we query just archive (delayed) data on BSC (Binance Smart Chain) network.
Refer to the dataset documentation for possible options to apply on this level.
By selecting the top element EVM we completely define what we can query below this element.
Apparently, Bitcoin and Ethereum have different schema and data, so we can not query them exactly the same way.
Cube Element
Blocks(limit: {count: 10}) is what we call "Cube", particulary because we
use OLAP methodology, applying
metrics. Cube defines what kind of facts we want to query, in this case
we interested in blocks. Cubes are generally different for different types of blockchains.
Dimension Element
Block {
Date
}
is the dimension part of the query. It defines the granularity of the data that we query. This example queries the data per-date manner. If we would need to have it per block, we would use:
Block {
Number
}
Query can make many dimensions. Result will have granularity combined from all dimensions used. Query for transactions by block date and transaction hash will group all result by block date AND by transaction hash:
Block {
Date
}
Transaction {
Hash
}
Metric Element
count is a metric. It is optional, defines "what we want to measure".
If it is missing, the results will give all data with the selected dimensions.
Note that the presence of at least one metric changes the way how query operates. Compare these two queries:
The following query returns as many entries as blocks we have, with the date for each block:
Block {
Date
}
This return counts of blocks per every date (aggregated by all blocks) :
Block {
Date
}
count
Refer to the metric tutorial for more details how you can use them.
Attributes
limit: {count: 10} is an attribute, defining limit on the data result size.
There are several types of attributes, described in the sections:
Correctness
To be correctly executed, the query must conform with the following requirements:
- query must conform the schema. When you build query in the IDE, it will highlight all errors according to schema
- query should not violate principles described above and some natural limitations of the database capabilities. For example, you can not fetch a million result in one query, you have to use offset and limits.
- query should not consume more than available resources on the server. We use points to calculate consumed resources.
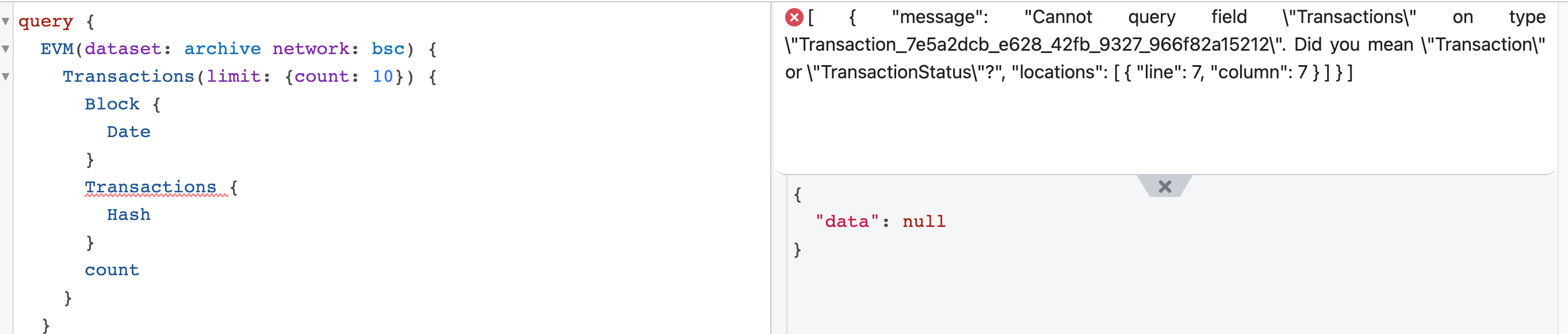
If query can not execute, the result contains the errors in the results
This screen shows the highlighted error in the query and the resulting response: